As use of clusters/compute grids becomes more diversified, the industry is witnessing a convergence of high-throughput computing with high-performance computing. Nitro is a highly powerful, yet simple task launching solution that operates as an independent product, but can also integrate seamlessly with any HPC scheduler. Instead of requiring individual job scheduling, Nitro enables high-speed throughput on short computing jobs by scheduling only once for a large set of jobs.
Enables 100x faster throughput on short jobs
Supports thousands to billions of tasks in HTC or SOA workloads
Removes launch speed bottleneck and achieves significant improvement in overall system efficiency
How It Works
Nitro Works with Existing Schedulers
Nitro coexists with other HPC schedulers such as Platform LSF, PBS Pro, Moab/TORQUE, UGE, and SLURM. Because of Nitro’s staged coordinator-worker architecture, Nitro throughput increases with the number of cores allocated to the session. Simple syntax to use: one line = one task and a line contains an executable command. If current HTC job syntax requires conversion, a tasks-filter can be created to automatically reformat into ‘task’ definition syntax. When Nitro is used with Moab, TORQUE, or SLURM, it can be integrated with the Viewpoint portal for ease of use and more streamlined submission and management.
Optimal Use
Nitro is highly valuable to administrators who want drastically improved throughput on serial jobs or single node parallel jobs that run for milliseconds to minutes, though use cases of longer run times can see a benefit with Nitro as well. There are multiple use cases where if even a fraction of the workload matches the high-throughput use cases covered by Nitro, there is still significant overall system efficiency gained by running Nitro.
Provides simple user job submission (API-based submission and monitoring is available in Nitro for SOA)
Works on existing clusters with no application modifications
Runs with any HPC scheduler or as a stand alone service
Tasks can be named, given labels and are indexed for easy parsing and task identification
Tasks on failed workers are moved to functioning workers
Checkpoint tasks to enable restart in case of task interruption
Dynamically add/remove nodes to/from a Nitro session to provide load balancing and meet Service Level commitments
Linger Mode allows ongoing submission to an open session for near real-time workloads
Track Nitro session status in real time (tasks completed, pending, failed, worker health, etc.) via CLI or Viewpoint
Reports on task details (resources utilized, task run time, standard error, etc.)
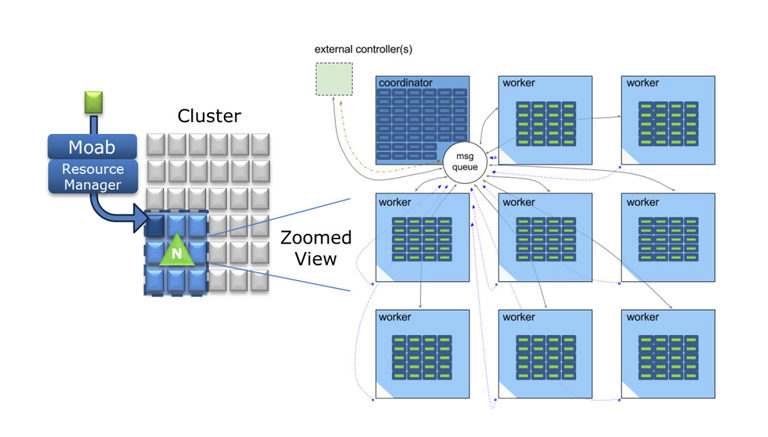
How Nitro Works
A user submits a Nitro job to the job scheduler. Nitro operates by using its scheduler-allocated nodes for a session where it executes tasks (short-running HTC jobs). Nitro starts a coordinator on the first node in the session. It reads a set of task definitions from a task file and delegates task assignments to each worker running on an allocated node in its session over a high-speed message bus. Each worker executes the assigned tasks, reports back to the coordinator for a new assignment, and so on until all tasks are completed.
Each Nitro job submission can build, activate, and tear down a new Nitro session. This is seamless and requires no management by administrators or users. Individual Nitro sessions can scale up to a few hundred nodes (enough to launch hundreds of thousands of tasks per second); a given cluster can simultaneously host as many or as few Nitro sessions as need dictates.
Nitro Benchmarks
In benchmark testing, Nitro displayed a completion rate of 200 tasks per second per core, outperforming other leading schedulers by 54x. In an optimized environment it ran 500 tasks per second per core, putting it over 100x faster than competition. In another performance test, Nitro was able to run over a billion tasks on a single server over a weekend. Clearly this tool puts high throughput performance into your computing center and is ready to handle any volume you can throw at it.